Modélisation de données : quel modèle choisir à chaque étape de la vie de la donnée ?

Chaque organisation désireuse de valoriser ses données et de mettre en place une stratégie Data Driven a pour objectif de structurer ces données de manière à les rendre accessibles, afin qu’elles puissent servir de fondement aux prises de décisions.
Les données sont considérées comme structurées lorsqu’elles sont régies par un data model (modèle de données). Un data model fournit aux données qui le compose une structure conceptuelle et organisationnelle. Nous allons nous intéresser dans cet article à trois types de modèles de données ayant chacun un rôle particulier lors de l’exploitation de la donnée au sein d’une organisation :
- l’espace staging
- les data models Third Normal Form (3NF)
- les data models en étoile
Afin de comprendre quand et pour quelles raisons mettre en place l’un ou l’autre des data model cités ci-dessus, il est nécessaire d’étudier le cycle de vie de la donnée.
Comprendre le Cycle de Vie de la Donnée
Comprendre le cycle de vie de la donnée est essentiel pour plusieurs aspects de la gestion des données dans une organisation. Cela permet d’optimiser la collecte et le stockage des données, en évitant l’accumulation inutile et en réduisant les coûts. Une bonne compréhension du cycle assure également la qualité et la fiabilité des données, cruciales pour des décisions stratégiques éclairées. Elle joue un rôle clé dans la conformité aux réglementations en constante évolution, comme le GDPR, particulièrement dans les phases de collecte, stockage et archivage. De plus, elle facilite l’exploitation efficace des données, en choisissant les bons outils et techniques d’analyse adaptés à chaque étape. La sécurité des données est également renforcée à chaque étape du cycle, minimisant les risques de violation et de perte d’informations. Enfin, comprendre ce cycle aide les organisations à s’adapter rapidement aux changements technologiques, garantissant une gestion des données à la fois efficace et actuelle.
Chaque data model proposé correspond à une des trois étapes du cycle de vie de la donnée : Bronze, Silver et Gold.
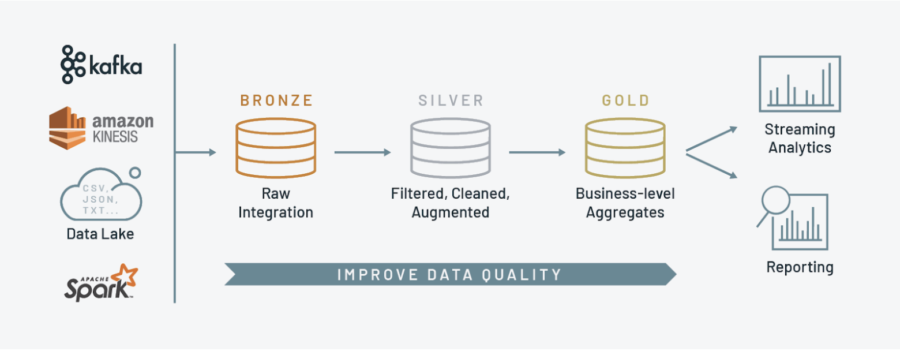
Le modèle de staging au service de l’intégration des données
À l’étape initiale du traitement de la donnée (phase Bronze), celle-ci se présente sous forme de données brutes ou “raw” data. C’est donc une donnée brute, non traitée, structurée, semi-structurée ou non structurée. Durant cette phase, l’aspect critique réside dans la capacité à ingérer toutes les données disponibles, indépendamment de leur format, leur origine, etc.
L’utilisation d’une zone de staging dans le traitement de la donnée offre plusieurs avantages importants :
- Intégration des Données Brutes : À l’étape bronze, les données peuvent provenir de sources diverses et être dans des formats variés. L’espace staging permet d’intégrer ces données brutes de manière centralisée avant de passer à des étapes de transformation plus avancées.
- Préparation des Données : La zone de staging offre un espace dédié pour nettoyer, valider et préparer les données brutes. Cela inclut souvent des opérations telles que l’élimination des doublons, la correction des erreurs de format, et la normalisation des données.
- Traçabilité et Audit : La zone de staging permet de mettre en place des mécanismes de traçabilité et d’audit pour enregistrer les étapes de préparation des données. Cela facilite la vérification des processus et la résolution d’éventuels problèmes.
- Flexibilité : L’espace de staging offre une flexibilité pour traiter des données de différentes natures et provenances. Elle peut s’adapter à des schémas de données variés et à des formats différents.
- Contrôle des Modifications : Avant de déplacer les données vers des étapes ultérieures du traitement, la zone de staging permet de contrôler les modifications apportées aux données. Cela facilite la gestion des versions et l’historisation des données.
En résumé, l’utilisation d’une zone de staging dès l’étape initiale offre une méthode structurée pour intégrer, nettoyer et préparer les données brutes avant de les introduire dans des processus plus avancés. Elle contribue à assurer la qualité, la cohérence et la fiabilité des données tout en minimisant les risques liés aux opérations de traitement.
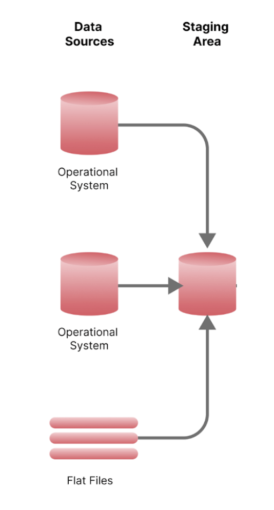
Représentation schématique de l’espace staging alimenté par diverses sources
Le modèle de données 3NF au service de l’amélioration de la donnée ?
Une fois la donnée stockée dans l’espace staging, l’étape suivante d’intégration de la donnée est l’étape Silver qui correspond au stockage logique et structuré de la donnée staging pour laquelle la création d’un data model 3NF est requise. C’est à cette étape que la véritable intégration des données peut commencer. L’objectif est de stocker les données provenant de l’espace staging “en vrac” de façon logique et structurée.
Qu’est ce que la troisième forme normale (3NF) ?
Un modèle de données en Troisième Forme Normale (3NF) est une représentation structurée des données qui suit les principes de la troisième forme normale en modélisation relationnelle. Les caractéristiques principales de ces types de modèles sont les suivantes :
- Structure Relationnelle : Le modèle en 3NF s’inscrit dans le cadre des bases de données relationnelles. Les données sont organisées en tables, chaque table ayant une clé primaire unique qui identifie de manière unique chaque enregistrement.
- Dépendance Fonctionnelle : En 3NF, chaque colonne non clé (attribut) d’une table doit dépendre entièrement de la clé primaire de cette table. Autrement dit, chaque attribut non clé doit être fonctionnellement dépendant de toute la clé primaire, et non pas d’une partie seulement.
- Élimination des Dépendances Transitives : La 3NF vise à éliminer les dépendances transitives. Cela signifie qu’aucun attribut non clé ne peut dépendre d’un autre attribut non clé à l’intérieur de la même table.
Pourquoi utiliser un tel modèle à l’étape du nettoyage, du filtre ou de l’amélioration des données (silver) ?
L’utilisation d’un modèle en Troisième Forme Normale (3NF) pour traiter la donnée à l’étape silver (étape de création d’un data warehouse) offre plusieurs avantages :
- Réduction de la Redondance : En adoptant la 3NF, il est possible de réduire davantage la redondance des données, garantissant que chaque information est stockée de manière non redondante et minimisant l’espace occupé.
- Structuration Claire : La 3NF favorise une structuration claire des données. Chaque table est conçue de manière à ce que chaque colonne dépende uniquement de la clé primaire, ce qui facilite la compréhension et la maintenance des schémas de données.
- Performance des Requêtes : En normalisant les données à l’étape silver, les opérations de requêtes deviennent plus efficaces. Les relations entre les tables sont mieux définies, ce qui simplifie la rédaction de requêtes complexes et améliore la performance d’extraction d’informations spécifiques.
- Adaptabilité aux modifications : La 3NF offre une certaine souplesse pour gérer les modifications ultérieures. À mesure que de nouvelles données sont ajoutées ou que les besoins évoluent, le modèle 3NF peut être ajusté sans trop de difficultés.
- Maintien de l’Intégrité des Données : La structure en 3NF contribue à maintenir l’intégrité des données. En minimisant les dépendances entre les colonnes, on réduit le risque de données incohérentes ou contradictoires.
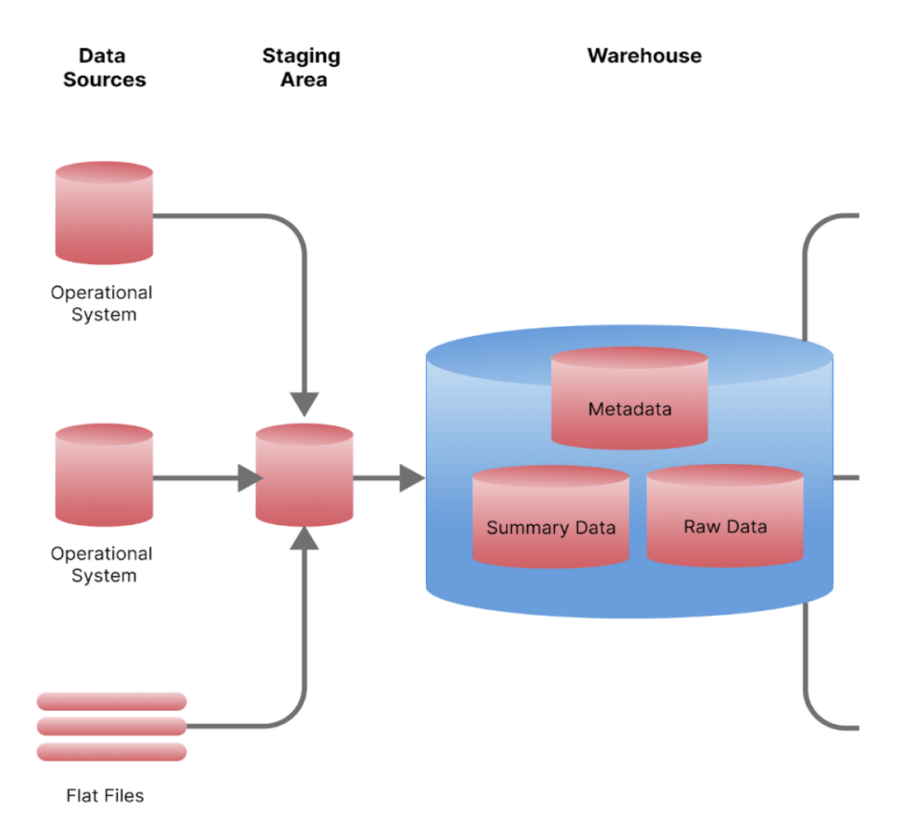
Les données du modèle 3NF constitue un warehouse structurée en aval de l’espace staging
Bien que les modèles de données en Troisième Forme Normale (3NF) aient des avantages en termes de normalisation et d’intégrité des données, ils peuvent ne pas être optimaux pour alimenter directement des dashboards contenant des insights business.
Les limites d’un modèle 3NF
En effet, l’utilisation directe des données en sortie d’un modèle 3NF peut poser des défis pour les besoins analytiques immédiats :
- Complexité des requêtes : Les modèles 3NF peuvent rendre les requêtes analytiques plus complexes en raison de la dispersion des données sur plusieurs tables normalisées. Les requêtes nécessitent souvent des jointures et des agrégations importantes, ce qui peut entraîner des performances suboptimales.
- Difficulté d’Interprétation : Les données en 3NF peuvent être plus difficiles à interpréter pour les utilisateurs non techniques.
- Compatibilité avec les Outils d’Analyse : L’utilisation directe de données en 3NF peut nécessiter des transformations supplémentaires pour s’adapter à ces outils.
- Espace de stockage : Bien que la 3NF favorise la réduction de la redondance, elle peut entraîner une utilisation plus importante de l’espace de stockage en raison de la normalisation.
- Performance des Jointures : Les jointures entre tables dans un modèle 3NF peuvent être plus nombreuses et complexes, ce qui peut entraîner des problèmes de performance, en particulier dans des environnements à grande échelle.
En conséquence, pour optimiser l’alimentation de dashboards contenant des insights business, il est souvent recommandé de transformer les données à partir d’un modèle 3NF vers un modèle en étoile (étape Gold), mieux adapté aux besoins analytiques. Cette transition vise à optimiser la structure des données pour les besoins spécifiques des analyses avancées et des rapports dans un environnement de type data warehouse.
Le modèle de données en étoile au service des enjeux business
Un modèle de données en étoile (Star Schema) est un type de schéma de conception de base de données utilisé principalement dans les datamarts (sous-ensemble d’un data warehouse) pour faciliter les opérations d’analyse et de reporting. Il se caractérise par une structure organisée autour d’une table centrale de faits (fact table) liées à des tables de dimensions (dimension tables) à l’aide de clés primaires/étrangères.
Les composants clés d’un modèle de données en étoile
- Table de Faits (Fact Table) : C’est la table centrale du modèle en étoile. Elle contient les mesures numériques, également appelées faits, que l’on souhaite analyser. Ces mesures peuvent être des données quantitatives, comme les ventes, les revenus, les quantités, etc.
- Tables de Dimensions (Dimension Tables) : Ces tables contiennent les attributs des dimensions qui fournissent du contexte et des détails autour des mesures de la table centrale de faits. Par exemple, si la table centrale de faits concerne les ventes, les tables de dimensions pourraient inclure des informations sur les produits, les clients, les temps, etc.
- Clé Étrangère (Foreign Key) : La table centrale de faits inclut généralement des clés étrangères faisant référence aux clés primaires des tables de dimensions. Ces clés étrangères établissent les relations entre les faits et les dimensions.
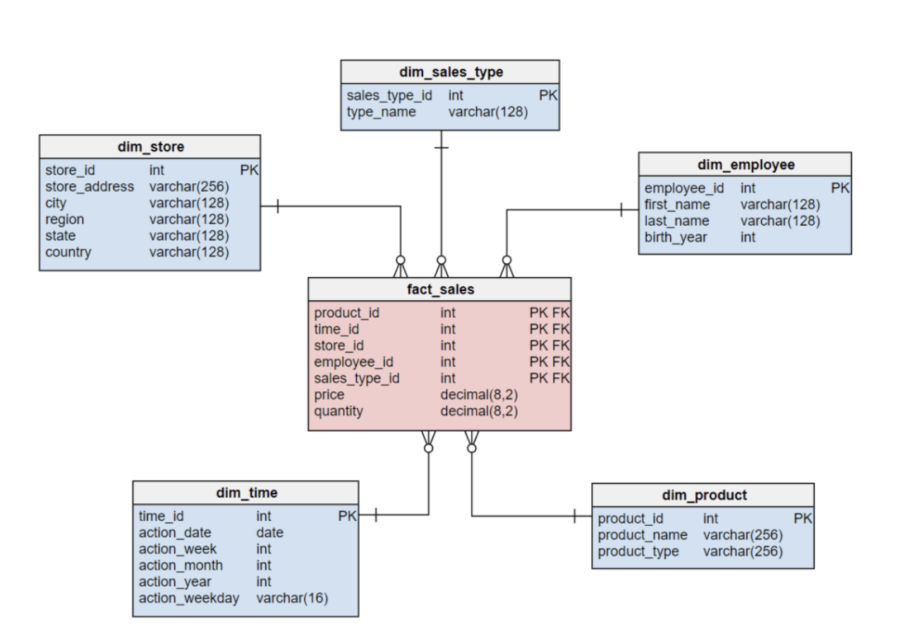
Exemple de modèle en étoile où chaque table de dimension est liée à la table de fait par une clef primaire
Pourquoi utiliser un tel modèle au service des enjeux métiers ?
- Simplicité des requêtes analytiques : Un modèle en étoile simplifie les requêtes analytiques en séparant les mesures numériques (dans la table centrale de faits) des dimensions descriptives (dans les tables de dimensions). Cela facilite la rédaction de requêtes complexes et améliore la lisibilité du code SQL ou des expressions de requête.
- Performances Améliorées : Les modèles en étoile sont conçus pour optimiser les performances des requêtes analytiques. En regroupant les données autour de la table centrale de faits, qui contient les mesures numériques, les opérations d’agrégation sont plus efficaces, ce qui se traduit par des temps de réponse plus rapides pour les analyses.
- Structure Adaptée à l’OLAP : Les modèles en étoile sont bien adaptés aux opérations d’analyse multidimensionnelle (OLAP), couramment utilisées dans les environnements de data warehousing. La structure en étoile facilite la navigation à travers les dimensions pour explorer les données sous différents angles.
- Facilité d’Extension : En ajoutant de nouvelles dimensions ou mesures, un modèle en étoile reste relativement facile à étendre. Cela permet de répondre aux besoins changeants des utilisateurs et de l’entreprise sans perturber fondamentalement la structure existante.
- Séparation entre dimensions et faits : La séparation claire entre les mesures et les dimensions simplifie la conception et la maintenance du modèle. Les modifications apportées aux dimensions n’ont généralement pas d’impact significatif sur les mesures, et vice versa.
- Optimisation de l’Espace de stockage : Un modèle en étoile peut parfois permettre une optimisation de l’espace de stockage, car il réduit la redondance et facilite la compression des données, ce qui peut être crucial dans les environnements de grande échelle.
- Compatibilité avec les Outils d’Analyse : Les outils d’analyse et de business intelligence sont souvent conçus pour fonctionner efficacement avec des modèles en étoile. Cette compatibilité simplifie l’intégration de ces outils dans l’écosystème de données.
En résumé, l’utilisation d’un modèle en étoile après un modèle 3NF à l’étape Gold permet de tirer parti des avantages spécifiques d’un schéma dimensionnel pour les analyses avancées et les rapports, tout en maintenant une base de données normalisée à partir de l’étape 3NF. Cette approche offre une combinaison de structure organisée, de performances optimisées et de flexibilité pour répondre aux besoins évolutifs des utilisateurs.
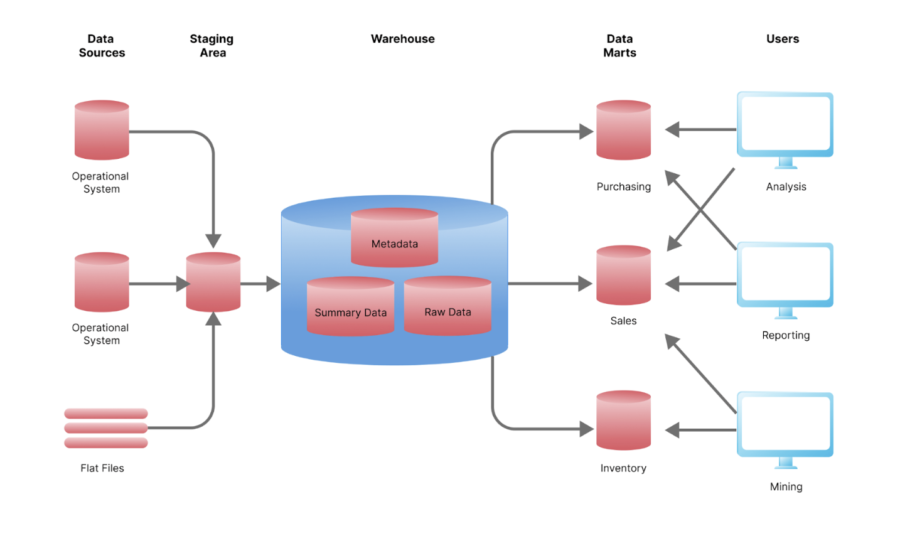
Représentation du cycle de vie de la data complet. On y retrouve les datamarts, modèles de données en étoiles associés à des sujets business spécifiques, qui alimentent les outils d’analyse en bout de chaîne.
Conclusion
De l’intégration initiale des données brutes (Bronze), à leur structuration en phase d’amélioration (Silver), jusqu’à leur optimisation pour l’analyse et le reporting (Gold), chaque modèle contribue de manière unique à la valorisation des données.
Ce processus structuré est essentiel pour transformer les données en insights stratégiques, soutenant ainsi une prise de décision efficace et data-driven. Avec l’évolution des technologies et l’accent sur la sécurité des données, on peut s’attendre à voir émerger de nouveaux modèles de données. Ces développements promettent de renforcer la flexibilité, l’efficacité et la conformité des modèles de données, répondant aux besoins changeants des entreprises dans un environnement de données en constante évolution.
Dans ce contexte en constante évolution, une compréhension approfondie des différents modèles de données et de leur application optimale à chaque étape de la vie de la donnée restera un atout majeur pour toute organisation aspirant à une stratégie data-driven efficace et pérenne.
